NVIDIA에서 오픈소스 소프트웨어로 제공되는 머신러닝 모델 inference 서버
1. 아키텍쳐
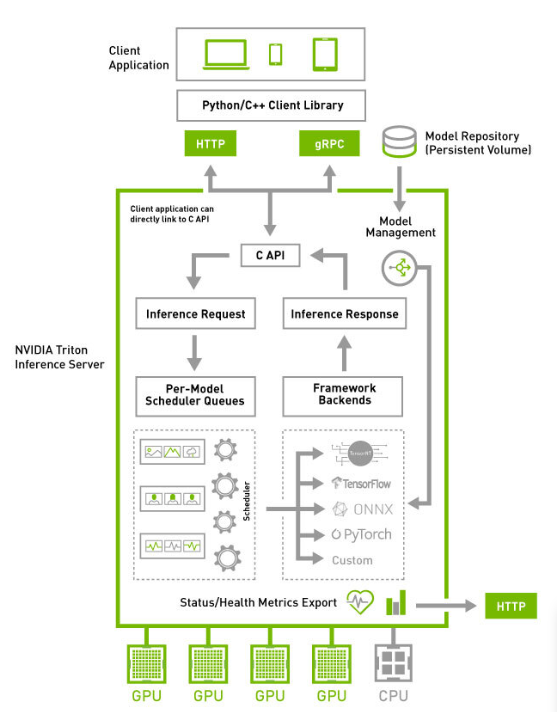
Model Repository에 모델 파일들을 올려놓으면 클라이언트가 api로 추론 요청 후 결과를 받을 수 있다.
간단한 사용 예

2. Model Repository [—model-repository]
서빙할 모델 파일들을 저장. 서버의 로컬 또는 클라우드 저장소도 가능
launch할때 옵션으로 여러 개 선택 가능


2-1. Model Management [—model-control-mode]
- none
- Repository의 모든 모델 로드, 가동 중에는 Rspository 변경 사항이나 management 요청을 무시
- explicit [—load-model]
- —load-model 옵션으로 명시된 모델만 로드, 없으면 아무것도 로드하지 않음
- poll [—repository-poll-secs]
- 모든 모델을 로드 후 주기적으로 변경 사항을 감지하여 재로드, management 사용 불가
2-2. Model Configuration
config.pdtxt 파일에 작성, 필수 옵션 = backend, max_batch_size, input, output


출처
https://peaceatlast.tistory.com/25
NVIDIA Triton 한 눈에 알아보기
GitHub - triton-inference-server/client: Triton Python, C++ and Java client libraries, and GRPC-generated client examples for go Triton Python, C++ and Java client libraries, and GRPC-generated client examples for go, java and scala. - GitHub - triton-infe
peaceatlast.tistory.com
https://github.com/triton-inference-server/server
GitHub - triton-inference-server/server: The Triton Inference Server provides an optimized cloud and edge inferencing solution.
The Triton Inference Server provides an optimized cloud and edge inferencing solution. - GitHub - triton-inference-server/server: The Triton Inference Server provides an optimized cloud and edge i...
github.com
'MLOps(DevOps)' 카테고리의 다른 글
| RabbitMQ [AMQP / MQTT 비교] (0) | 2025.11.12 |
|---|